
网站首页 站群工具 内容处理工具 正文
骷髅侠的标题采集工具,在做泛站群的时候可以将采集的到的数据直接作为标题使用。
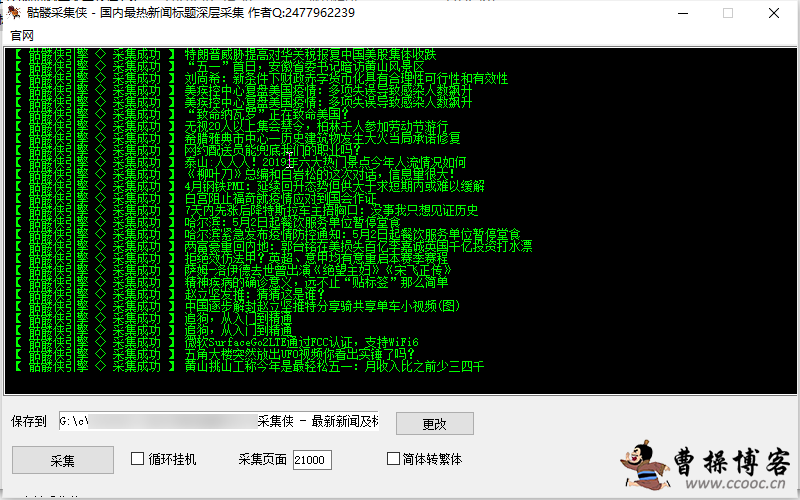
程序说明
1、内置独家的新闻挖掘接口数据
采集软件市面很多,采集软件很轻松能写出,但是技术点不在程序逻辑怎么编写,而在于怎么发现高质量的采集源,骷髅采集侠能嗅探采集到的2005年-2019年15年的国内新闻源文章,从文章的数据容量来说,远远的满足了站群对文章的需求,对文章有严苛要求的用户,对文章质量要求会更高,骷髅采集侠采集的文章能追溯到15年前,很多搜索引擎因为服务器数据量庞大,都会逐步删除裁剪掉十年前的收录索引,因此采集几年十年前的文章发布,对蜘蛛来说,可视为原创。
2、为站群系统设计开发
骷髅采集侠在保存内容的时候,会自动生成时间戳TXT,每个txt容量为50Kb,超出容量后会重新创建txt继续保存,这个功能是为站群设计,在大数据高频率运行读取的站群系统,如果TXT容量大,比如有的新手站长在放置txt的时候,文件几兆甚至有的几十兆,站群在读取txt数据的时候会造成cpu很高,甚至堵塞,为了让站群更高效率运行,我建立大家在放置txt的时候文件大小不要超过50kb,不光是文章,关键词域名等文本txt也要严格按照这个文件大小。
3、挂机嗅探采集技术
第一次运行骷髅采集软件,建议设置采集深度21000,软件会自动全部采集2005-2019全部新闻,采集完成后,重启下软件,采集深度请设置成5,勾选循环,点击开始,软件会自动的循环嗅探,采集当前国内外最新发布的新闻,采集的速度非常的快,国内新闻源的文章发布出来1-5秒,软件就会全自动的执行采集。
4、自动转繁体
骷髅采集侠能把采集下来的标题或正文,自动转码,支持转化繁体中文字体。
5、整篇文章自动拆分段落
采集的文章自动拆分成段落,存放到段落txt,提供给站群输出段落标签。
使用说明
骷髅采集侠分成了 标题采集 跟 正文采集两个软件,操作使用上完全相同。
1、设置参数
骷髅采集侠参数设置很简单,只需要设置保存的路径,采集生成的txt会自动保存在这个路径下面。
骷髅侠软件的各类站群版本,txt的路径相同
根目录/juzi 下面放标题 对应标签
根目录/juzi2 下面放正文 对应标签
2、初始采集
设置深度21000,可采集大约100万篇新闻,当你觉得采集的文章量满足你的需求时关闭软件。初始采集能给你采集到基础的文章txt容量,比如你搭建个蜘蛛池,5000个txt就够了,就没有必须深层采集太多txt
3、循环挂机
初始采集结束之后,重启软件,把采集深度设置成5,这时候软件会全自动的扫描互联网新闻源最新发布的新闻执行采集。
- 上一篇: 多行批量字符替换器
- 下一篇: 骷髅采集侠:百万新闻内容采集软件
必看说明
- 本站中所有被研究的素材与信息全部来源于互联网,版权争议与本站无关。
- 本站文章或仅为文本内容原创,非程序原创。如有侵权、不妥之处,请联系站长第一时间删除。敬请谅解!
- 本站所有内容严格遵守国家法律的条例,所有研究的算法技术均来源于搜索引擎公开默认允许用户研究使用的接口。
- 阅读本文及获取资源前,请确保您已充分阅读并理解《访问曹操SEO网站需知:行为准则》。
- 本站分享的任何工具、程序仅供学习参考编写架构,仅可在本地的虚拟机内断网测试,严禁联网运行或上传搭建!
- 任何资源必须在下载后24个小时内,从电脑中彻底删除。不得传播或者用于其他任何用途!否则一切后果用户自负!
- 转载请注明 : 文章转载自 曹操资源网 骷髅采集侠:标题深层采集软件
- 本文标题:《骷髅采集侠:标题深层采集软件》
- 本文链接:http://www.ccooc.cc/280.html
猜你喜欢
- 2021-01-13 pyhton新浪采集源码
- 2020-05-02 骷髅采集侠:百万新闻内容采集软件
- 2020-05-02 多行批量字符替换器
- 2020-05-02 多行批量字符替换器
- 2020-05-02 TXT文本内容批量合并器
- 2020-05-02 TXT文本多余空行过滤器
- 2020-05-02 批量关键词组合工具
- 2020-04-30 无需联网ai伪原创工具
- 2020-04-16 智能AI文章伪原创系统
- 2020-04-15 批量进行内容替换PHP源码
欢迎 你 发表评论:
- 05-26警惕“冒用身份”的电信网络诈骗
- 05-11PHP使用纯真IP数据库输出ip位置
- 05-11ChatGPT的高效应用:指令大全
- 05-10堤防“瑞熙工作室”利用QQ及微信诈骗
- 05-10手机狐狸网资讯站群程序
- 05-10使用php在拼音转文字时过滤掉标点符号及英文字符
- 05-10买卖备案域名的法律规定
- 05-10泛目录站群的操作方法及注意事项
- 2007℃小米浏览器禁止网址访问的处理方法
- 859℃分析超度站群实现百度本周收录较多的站点
- 709℃免费的百度SEO搜索点击程序
- 699℃网站如何才能快速收录?
- 688℃我站最新联系方式通知
- 668℃搜狗推送链接引蜘蛛软件:Sougou推送程序
- 667℃CCbook小说站群无限制版
- 664℃使用Google账号接码指南
- 164℃警惕“冒用身份”的电信网络诈骗
- 141℃「百日行动」“断卡”行动持续发力
- 132℃遵纪守法:一起举报违法网址
- 342℃提防以免费做蜘蛛池为幌子卖域名的套路
- 522℃群内一切的私下交易行为,与我站无关!
- 176℃堤防“瑞熙工作室”利用QQ及微信诈骗
- 418℃提防“凤凰于飞”诈骗,加强网络安全认知!
- 502℃关于近期网站内容修改短期闭站的情况通知
- 文章归档
-
- 2023年5月 (17)
- 2023年4月 (45)
- 2023年3月 (23)
- 2023年2月 (9)
- 2023年1月 (11)
- 2022年12月 (9)
- 2022年11月 (4)
- 2022年10月 (33)
- 2022年9月 (41)
- 2022年8月 (19)
- 2022年7月 (19)
- 2022年6月 (20)
- 2022年5月 (9)
- 2022年4月 (42)
- 2022年3月 (65)
- 2022年2月 (1)
- 2022年1月 (4)
- 2021年12月 (23)
- 2021年11月 (2)
- 2021年10月 (4)
- 2021年9月 (22)
- 2021年8月 (70)
- 2021年7月 (1)
- 2021年6月 (21)
- 2021年5月 (28)
- 2021年4月 (1)
- 2021年3月 (42)
- 2021年1月 (8)
- 2020年12月 (34)
- 2020年11月 (15)
- 2020年10月 (39)
- 2020年9月 (107)
- 2020年8月 (37)
- 2020年7月 (22)
- 2020年6月 (46)
- 2020年5月 (120)
- 2020年4月 (76)
- 2020年3月 (81)
- 2020年2月 (69)
- 2020年1月 (14)
- 2019年12月 (38)
- 2019年11月 (11)
- 2019年10月 (25)
- 2019年9月 (2)
- 2017年10月 (1)
- 标签列表
- 站点信息
-
- 文章总数:1332
- 页面总数:1
- 分类总数:47
- 标签总数:337
- 评论总数:39
- 浏览总数:245225
本文暂时没有评论,来添加一个吧(●'◡'●)